Chapter 2 Describing Data
2.1 Statistics to Summarise Data
When we describe data, we typically have three questions:
- What do typical values look like?
- How clustered or dispersed are these values?
- In short: How are the values of a variable in a sample distributed?
2.1.1 Tables
Data that comes in categories—be they nominal or ordinal—can be easily summarised. Simply list possible values for a variable, together with the number of observations for each value.
- Can be used to summarise distributions of one nominal, ordinal or interval variable.
- Intervals must be constructed for interval-level variables (e.g. age, income).
- Absolute frequencies record the actual number of observations for each value.
- Relative frequencies record the proportional distribution of observations.
This is an example from our data:
| Frequency | Percent | |
|---|---|---|
| Coffee | 10 | 0.59 |
| Other | 2 | 0.12 |
| Tea | 5 | 0.29 |
| Frequency | Percent | |
|---|---|---|
| Highest | 5 | 0.29 |
| 4 | 1 | 0.06 |
| 3 | 1 | 0.06 |
2.1.2 Central Tendencies
One of the first questions that comes to our minds when we consider a variable is: What is a typical value for it? Intuitively it makes sense to chose a value that shows the central tendency of a variable. There are three different statistics that can help summarise the distribution of scores by reporting the most typical or representative value of it.
Mode
The mode is the value that occurs most frequently. You can use it for all kind of categorical data. There can be more than one mode and under this circumstance you would speak of multimodal data. In case the answer categories can be ranked, the mode does not need to be near the centre of the distribution. Finally, the mode is resistant to outliers.
For political scientists, the mode is a really important measure: We use it whenever we want to determine the winner of an election. When I asked you for your vote (if you had had the choice), this is how you responded.
| Frequency | Percent | |
|---|---|---|
| 1 | 0.06 | |
| Biden | 14 | 0.82 |
| Trump | 2 | 0.12 |
The modal candidate is clearly Biden for your class. Two students would have voted for Trump.
Median
The median is the value that falls in the middle of an ordered sample. Obviously, the measure cannot be used for nominal variables—they can not be ranked. The median is the 50th percentile point. This means that when you count all cases, half of the sample will be smaller than the median and the other half is larger than the median. When the sample size is even, the median is the midpoint between the two measurements in the centre.
By definition, the median is resistant to outliers: Irrespective of how small the smallest value or how large the largest one, the one value that splits the sample in half will remain always the same.

These are your responses to the question how many hours you think you should study. I chose the dark blue line to indicate the median value of the data. Overall, we have 17 responses in the data. If the number of respondents is odd, the median is the average between two central responses that come into questions.
Mean
The mean is the sum of the observations divided by the number of observations \[\begin{equation*} \bar{x} = \frac{x_1 + x_2 + \ldots + x_N}{N} = \frac{\sum_{i=1}^{N}x_i}{N} \end{equation*}\]
with
- \(\bar{x}\) being the mean of variable \(x\);
- \(\sum\) being the sum;
- \(i\) the individual cases (of x);
- \(N\) the number of cases. \end{itemize}
This all looks a bit fancy, but it is actually just a matter of understanding the notation. Conceptually, the mean is really straightforward—it is nothing different than the good old average.
The mean has a couple of interesting characteristics. It is only applicable to interval variables. The mean is a good measure of central tendency for roughly symmetric distributions, but it can be misleading in skewed distributions. Most importantly, the mean is really susceptible to outliers. There is a nice physical interpretation of the mean: it is the centre of gravity of the observations.
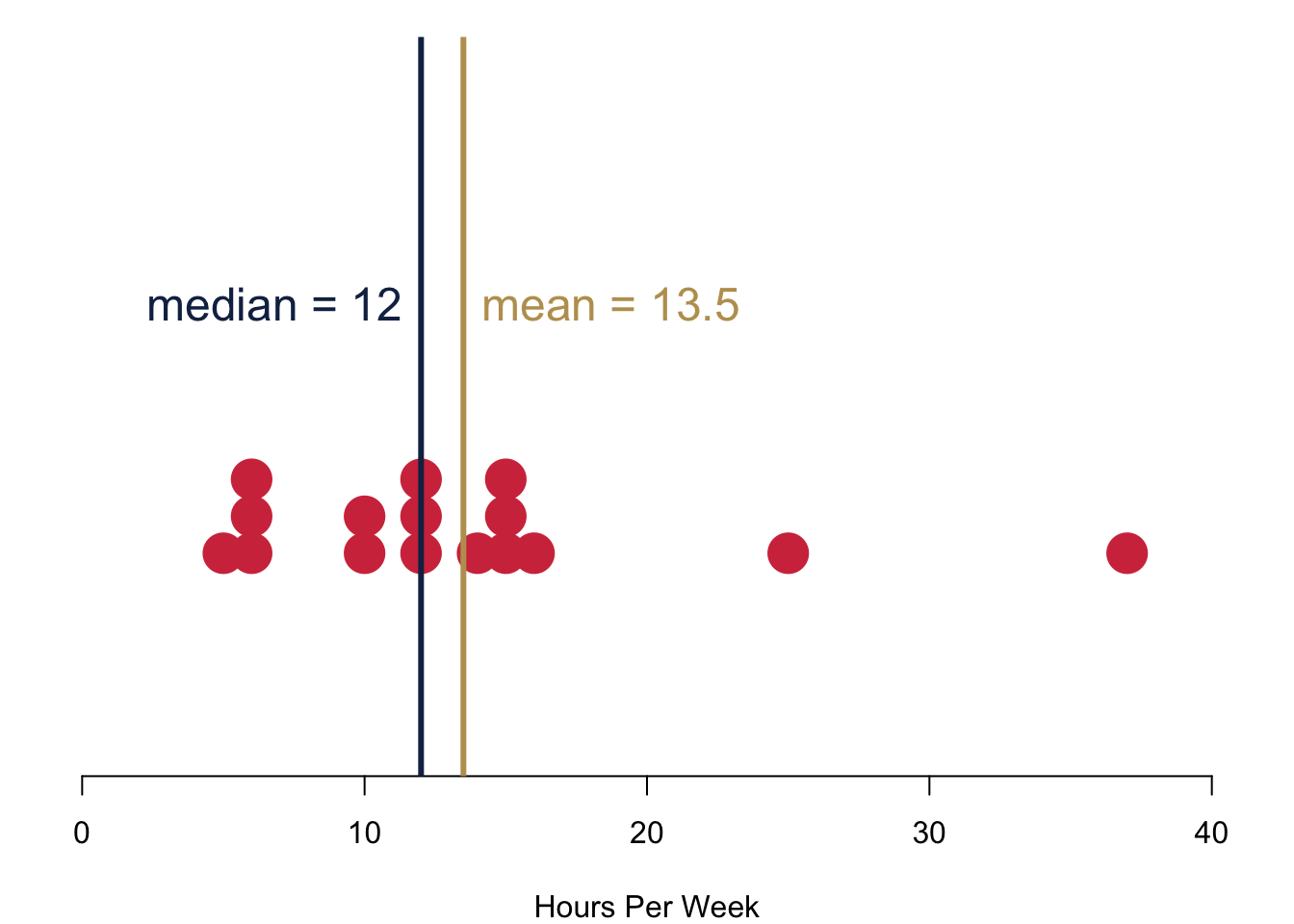
Take a look at your data for how many hours you actually study per week. Your mean is slightly higher than your median. Why is that so? Basically, those who study more than 20h per week have a considerable influence on the mean and push the mean to the right of the median.
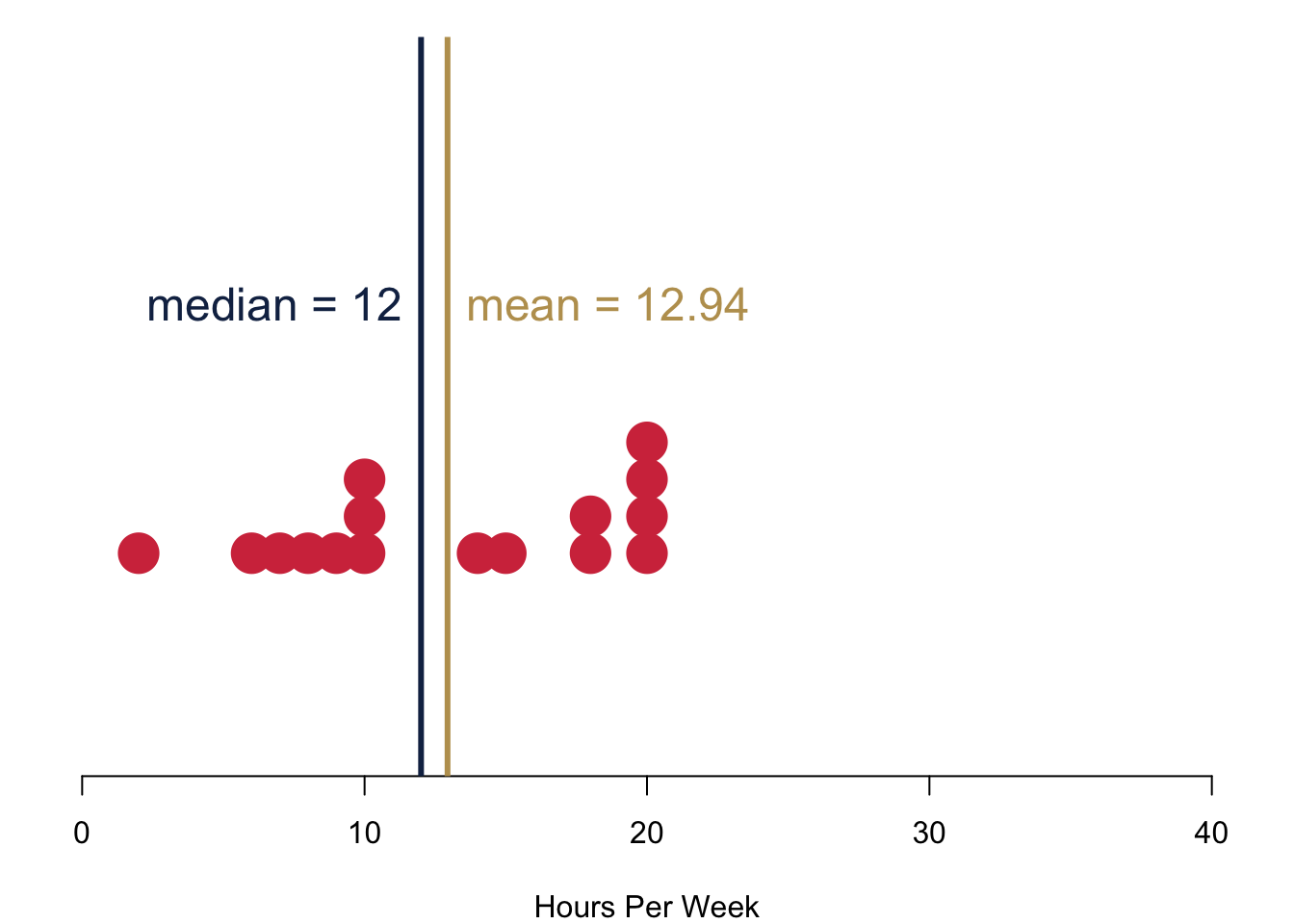
Compare your data with the data from the cohort in 2021: Here the median and the mean are closer together. Why is this so?
2.1.3 Spread
You now know how to chose a typical value that summarises your data. Next on the list is to characterise their spread. Are all values really close to one another? Are they far apart? Do many of them hang out on one side of the distribution, and are they far apart on the other side, i.e. is their distribution skewed?
To measure all this, we will now take a look at different measures of spread. In essence, they are statistics that summarise the variation around our average value. We will consider four different measures that all build on each other.
- Range: Difference between two values, typically the minimum and the maximum.
- Deviation: Difference of a value from the mean.
- Variance: Squared difference of a value from the mean.
- Standard Deviation: Square root of the squared difference of a value from the mean.
Range
The range is the the distance between the largest and the smallest values, i.e. maximum–minimum. It will be distorted by extreme values.
The interquartile range is another really important range. It covers the middle 50% of observations, so the range from the 25th percentile to the 75th percentile (lower quartile–upper quartile).
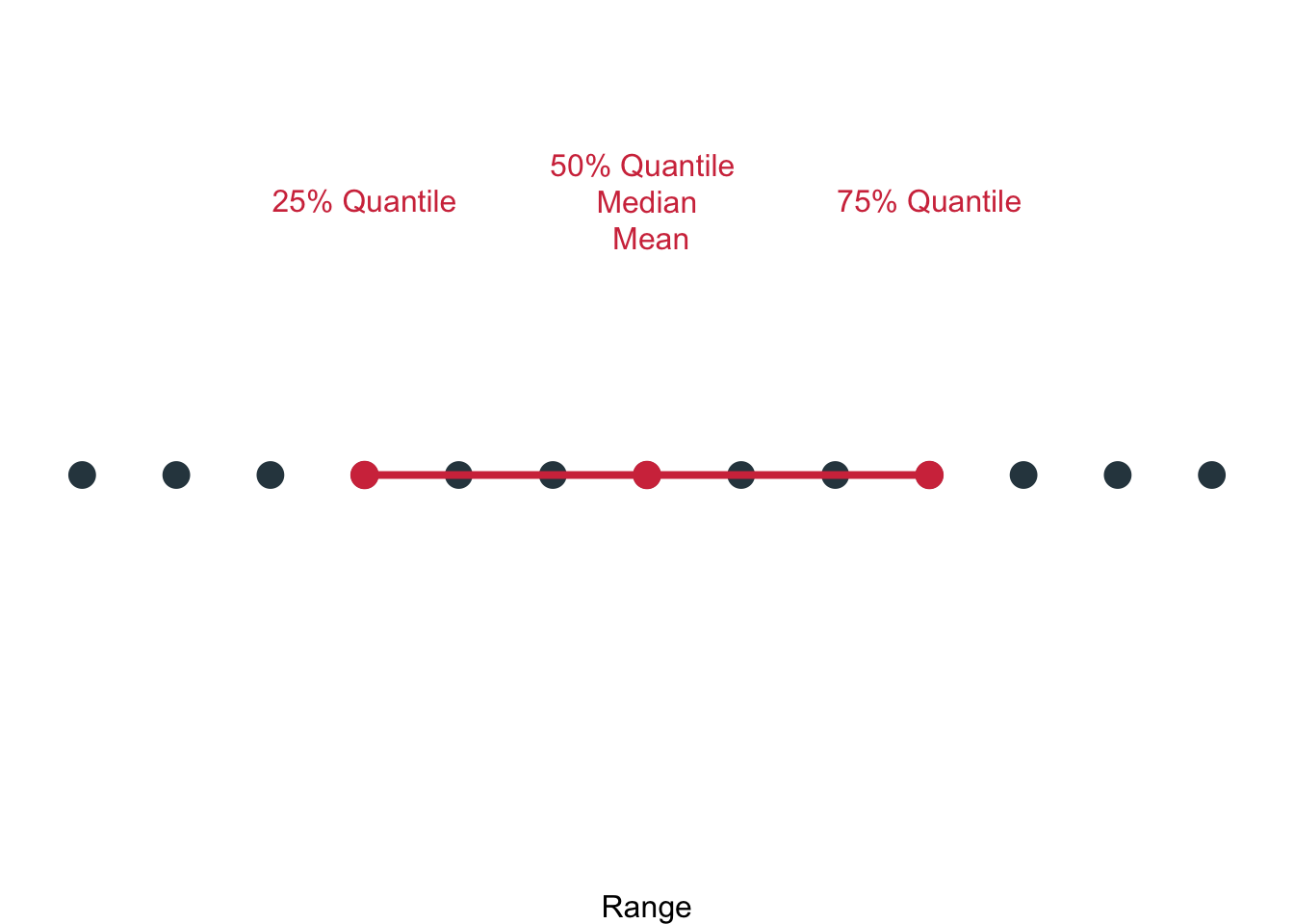
Here you can a number of concepts that we covered working together to describe the data: The 25% quantile, the 50% quantile, the 75% quantile, the median, the mean and the interquartile range.
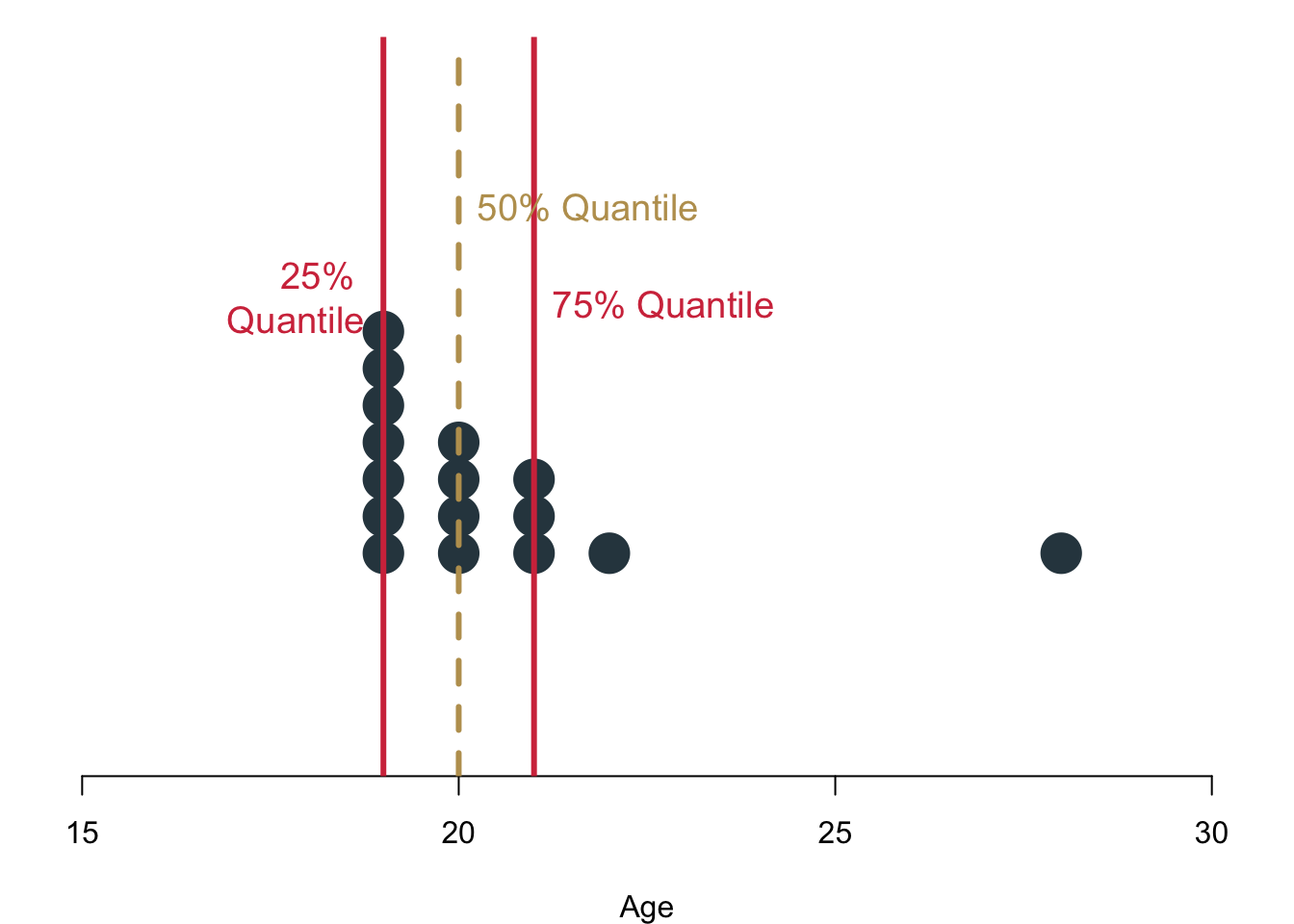
Let us describe some of your data, here how old you are. How large would be the interquartile range? Hint: the value is 2.
Deviation
The deviation of any observation is its difference from the mean. \[\begin{equation*} (x-\bar{x}) \end{equation*}\]
What is the sum of deviations? Do the maths with a couple of numbers on a piece of paper. \[\begin{equation*} \sum(x-\bar{x}) = ? \end{equation*}\]
Just in case some of you might still wonder about the \(\sum\) at this point: I put together a small video as a refresher. And it also shows the answer to the issue with deviations.
Apparently, the deviations always sum up to 0. The values keep canceling each other out. So what can we do? One solution would be to calculate the Mean Absolute Deviation \(\text{MAD}\). \[\begin{equation*} \text{MAD}=\frac{\sum(|x_i-\bar{x}|)}{n} \end{equation*}\]
In case you do not know the sign “\(|\)”: anything that is in between two “\(|\)” will always return its positive value. So \(|5| = 5\) and also \(|-5| = 5\).
Let us take a look at your data, here how much you actually study and how much you think you should study.
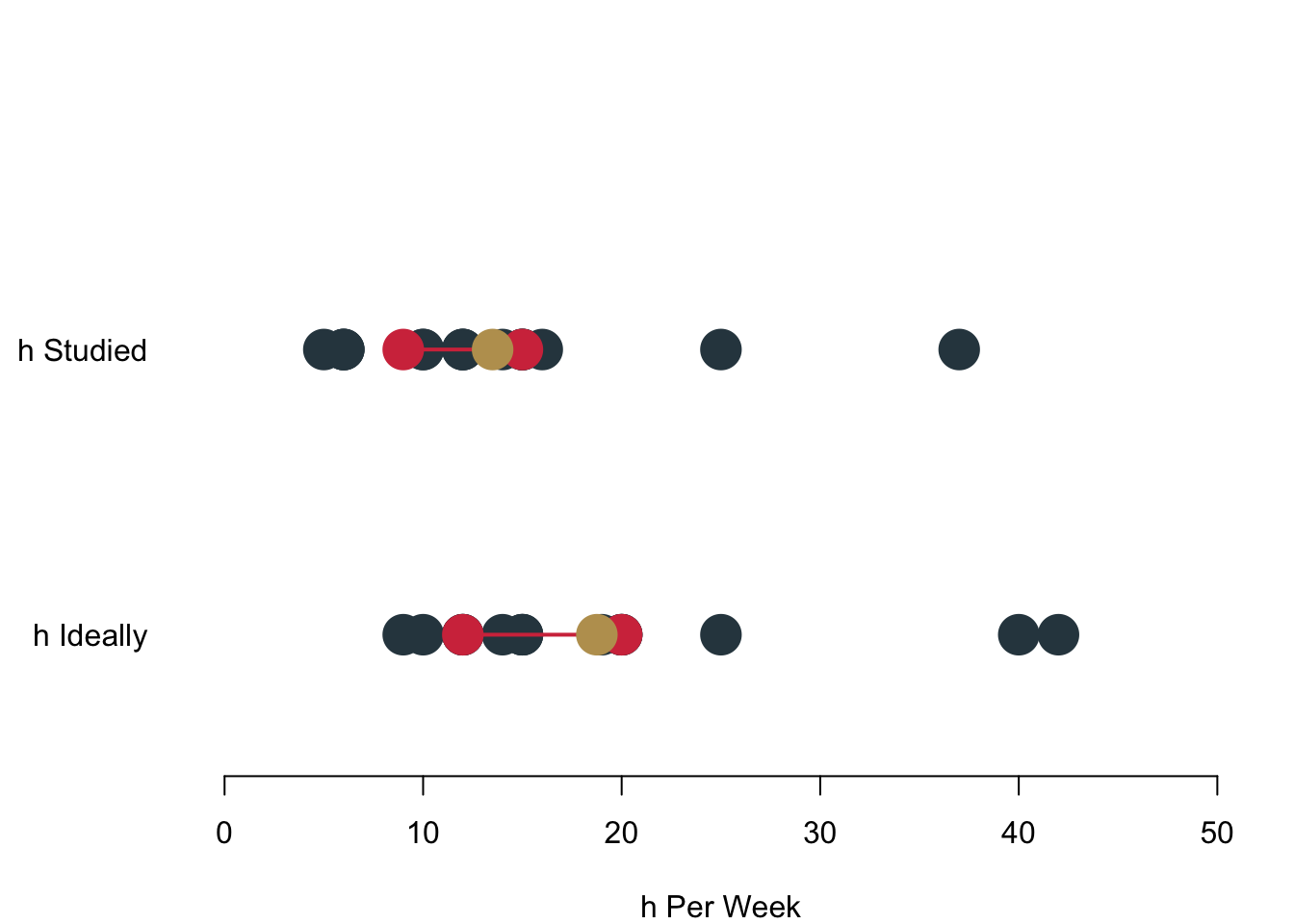 I am including again the interquartile range in red (which goes from where to where again?), and the mean in gold. When you do the maths you will find out that the \(\text{MAD}_{\text{actual}} = 5\) and \(\text{MAD}_{\text{ideal}} = 6.44\).
I am including again the interquartile range in red (which goes from where to where again?), and the mean in gold. When you do the maths you will find out that the \(\text{MAD}_{\text{actual}} = 5\) and \(\text{MAD}_{\text{ideal}} = 6.44\).
Variance
In practice, however, you will find that the Mean Absolute Deviation, is rarely used. Instead, you can often find the variance. It is basically the same as the \(\text{MAD}\), but different. To avoid the canceling out, we will square the distance of each value to the mean. And for arcane statistical reasons that are irrelevant for this class, we now subtract 1 from the overall cases \(n\) in the denominator. \[\begin{equation*} s^2=\frac{\sum(x_i-\bar{x})^2}{n-1} \end{equation*}\]
The variance of the actual number of hours you study is \(s^2_{\text{actual}} = 64.67\) and the variance for the number of hours you consider ideal is \(s^2_{\text{ideal}} = 93.93\). Contrast the difference between the two variances to the difference in the two \(\text{MAD}\)—it is much larger! The reason is simply that we are now taking the sum of the square of the distances and not just the absolute distances, which of course weighs much more for larger numbers. With the \(\text{MAD}\) each data point contributes an equal share to the overall measure of spread. For the variance, this is no longer true. Those data that are further apart from the mean will drive the variance to a much larger degree than those data that are close to the mean.
Standard Deviation
While the variance is already a big step forward in measuring spread, it has one important drawback: It is quite abstract and really hard to interpret. Ideally, we would want to understand the measure for spread on the same metric as the data themselves.
Doing so is straightforward. We simply take the square root of the variance—and the resulting standard deviation is in the metric of our data \(x\).
\[\begin{equation*} s=\sqrt{\frac{\sum(x_i-\bar{x})^2}{n-1}} \end{equation*}\]
In our running example—the number of h you study and the number of h you think you should study—this is what we get. The standard deviation for the former is \(s_{\text{actual}} = 8.04\) and the standard deviation for the latter is \(s_{\text{ideal}} = 9.69\).
Compare these values to the Mean Absolute Distances: \(\text{MAD}_{\text{actual}} = 5\) and \(\text{MAD}_{\text{ideal}} = 6.44\). They, too, are on the original scale. The standard deviation, however, is much more sensitive to outliers, which is a really desirable characteristic.
2.1.4 Ratios and Rates
Finally, ratios and rates.
Proportions
We start with something really simple, the proportion. It is calculated as
\[\begin{equation*} p = \frac{f}{N} \end{equation*}\]
with
- \(p\) being the proportion;
- \(f\) being the number of cases (frequency) in one category;
- \(N\) being the number of cases in all categories of the variable.
The proportion is useful if we want to answer a question like: What is the proportion of students having tea for breakfast?
\[\begin{equation*} p = \frac{5}{17} = 0.29 \end{equation*}\]
Percentages
You like percentages better? Simply multiply your proportions with \(100\).
\[\begin{equation*} P = \left( \frac{f}{N}\right) 100 = \left( \frac{5}{17} \right) 100 = 29.41\% \end{equation*}\]
Rates
A rate is really useful if you want to express for example how often a proportion occurs in a given amount of time. We can calculate the rate as \[\begin{equation*} r = \frac{\frac{f}{t}}{\frac{N}{u}} \end{equation*}\]
with
- \(r\) being the rate: the frequency per time in a certain set
- \(f\) being the number of cases (frequency) in one category
- \(t\) being the time under consideration
- \(N\) being the number of cases in all categories of the variable
- \(u\) being the unit under consideration
Let us advance step by step and wrap our head around this with the help of an example. We want to understand how many of you actually bought a computer during 2020. This simplifies our formula a bit.
\[\begin{equation*} r = \frac{\frac{f}{t}}{\frac{N}{u}} = \frac{\frac{\text{computer purchases}}{\text{one year}}}{\text{all students}} = \frac{\frac{5}{1}}{\frac{17}{1}} = 0.29 \end{equation*}\]
We can take this a little further and ask How many computers did 10 student buy in 2021?. To answer this question, we simply adapt the number of people in the unit and set \(u=10\).
\[\begin{equation*} r = \frac{\frac{f}{t}}{\frac{N}{u}} = \frac{\frac{\text{computer purchases}}{\text{one year}}}{\frac{\text{all students}}{\text{unit of 10 students}}} = \frac{\frac{5}{1}}{\frac{17}{10}} = 2.94 \end{equation*}\]
So 10 students bought 2.94 computers in 2021.
Growth
The last thing we want to look at is growth. In particular in economics, growth has a really prominent role, and a lot of theory is built around all kinds of growth related to different cash flow: GDP, GDP per capita, return on investments to just name a few. But of course, growth can also happen in other areas like literacy rates in low-income countries, unemployment or votes. Growth can be expressed as a percentage change.
\[\begin{equation*} G = \left(\frac{f_2 - f_1}{f_1}\right) 100 \end{equation*}\]
with
- \(G\) being the growth rate in a variable from time 1 to time 2
- \(f_1\) being the number of cases (frequency) at time \(t_1\)
- \(f_2\) being the number of cases (frequency) at time \(t_2\)
Again, let us take a look at our own data to understand what is going on here.
\[\begin{align*} G &= \left(\frac{f_2 - f_1}{f_1}\right) 100 \\ &= \left(\frac{\text{Purchases in 2022} - \text{Purchases in 2021}}{\text{Purchases in 2021}}\right) 100 \\ &= \left(\frac{-2}{5}\right) 100 = -40\% \end{align*}\]
Apparently, you were purchasing less computers during 2022, more specifically, the sales had a negative growth of \(G = -40\%\). It could be that a number of you bought a new computer when you started your university career back in 2021.
2.2 Data Management with R
To calculate all above, we first need to take a closer look at some data management this week.
2.2.1 Libraries
Libraries are functions that do not ship on board your original R programme. Instead, you have to get them from them internet.
Think of it like wanting to read a book. You first have to get it from a shop and bring it home, where you will add it to your book shelf in your own, personal library at home. In R, you can use the command install.packages() to download a package to your computer. If you execute the command, R might prompt you for a location—simply pick one that is close to you. Obviously, "name_of_library" is a placeholder here, so don’t try this at home with that particular code snippet, but replace it with the package you actually need.
install.packages("name_of_library")You now have downloaded the programme to your computer. Or, in other words, you have added the book into your bookshelf. However, you are not sitting in your lounge chair with the book in your hand, yet. For that, you would still have to go to the library in your house and get the book. This is exactly what we will be doing now with the R package. We will collect the package from our library and load it into the active work space.
library("name_of_library")2.2.2 Setting the Working Directory
R is quite stupid. It does not know where to look for files—be they R code or any other data—unless you really tell it where to look for a file.
Typically, we will instruct R to make its home in the exact place where you save your main R script with a function called setwd(). As its argument, you provide the path you are working in. For me on my office machine, this is how it looks like.
setwd('/Users/foo/PL9239 Intro_data_science/intro_data_science_homepage')Now, R will start looking for everything starting in that particular working directory. To see which working directory you are in, you can type
getwd()This step might seem a bit minor and technical, but it is the nr.1 rookie mistake to forget setting your working directory properly.
In case the idea of folders, files and working directories are still a bit confusing, here goes another video.
2.2.3 Reading Data
Working directories are particularly relevant if you want to read in data sets. Data mostly comes in two formats: comma separated values, or short .csv, and as a Microsoft Excel spreadsheet .xls. Most open data formats can be read in with a function that begins with read.foo. Of course, just reading it is not enough—you have to assign it to an object if you want to work with it, so we type for example:
csvdata <- read.csv("dataset1.csv")If we want to read in .xls data, we have to load a library that can help us with that. We will go with the readxl package. Again, we are assigning the data to an object so that we can call it later.
library(readxl)
xlsdata <- read_excel("dataset1.xls", sheet='sheet_foo')2.2.4 Saving Data
You can also save data. Let us create a toy data set again.
name <- c('Mark', 'Luise', 'Peter')
bike <- c('Mountainbike', 'Single_Speed', 'Racing_Bike')
hours <- c(4,7,8)
dat <- data.frame(name, bike, hours)Now save it.
save(dat, file = "toydata.RData")To check the magic of this we remove the data set and then try to call the object.
rm(dat)
dat## Error in eval(expr, envir, enclos): object 'dat' not foundNothing there.
load("toydata.RData")
dat## name bike hours
## 1 Mark Mountainbike 4
## 2 Luise Single_Speed 7
## 3 Peter Racing_Bike 8Tada! Worth noting at this stage, that when you use the native R way of saving data, R saves your actual object, here the object dat.
{kind=link}
You can of course also save data as an Excel spreadsheet.
library(writexl)
write_xlsx(dat, "toydata.xlsx")2.3 Describing Data Using R
Now, with a bit more of a background, we can calculate all of this week’s statistics. In R, this is really straightforward. I am showing you how I did that using your data. Of course, you cannot run the script yourselves, since I will not share the data.
2.3.1 Working with Data Frames
First, I load the data. Then I check which type it is: Apparently a data frame.
dat <- read.csv("../other_files/preparing_data/data/class_survey/lecture_survey_23.csv")
class(dat)## [1] "data.frame"Data frames are particularly useful, because we can call the individual variables simply by adding the $ symbol and then calling the name of the variable we are interested in. For example, if we want calculate how much you spend per week partying, we could simply multiply how much you spend on one night out and multiply it with how often you go out per week.
dat$spend * dat$partydays## [1] 80 60 20 24 120 30 50 10 15 90 24 30 20 40 40 30 452.3.2 Central Tendencies
You can take a look at the frequency of categorical data with the function table(). This is your data on how many days you are partying per week.
table(dat$partydays)##
## 1 2 3
## 8 5 4Indeed some party animals here. Now, what is the mode? We have to call a package for that function.
library(DescTools)
Mode(dat$partydays)## [1] 1
## attr(,"freq")
## [1] 8The output is a bit cryptic at first, but it tells us that the value 8 is the most frequent one.
For the median and the mean, let us take a look at a continuous variable. For example, how much money you spend when you go out. You call the median with median() and the mean with mean().
median(dat$spend)## [1] 20mean(dat$spend)## [1] 25.29412Stop for a second and think about the results:
- What does the relationship between the median and the mean tell us here?
- Is the distribution really symmetric?
- Is the distribution maybe skewed? If so, how?
2.4 Readings for This Week
Please read chapter 7 in Fogarty (2019). Chapters 4 and 5 are a good idea, but you do not necessarily have to.