Chapter 7 Comparing Apples and Oranges
All the tools that we have so far are nice and good. But there are more things that we would like to do with data. While we learned how to make statements about bivariate relationships, we often want to go beyond this. In our data, we might be interested to know the relationship between how many hours you study and how often you go out per week. But it might be, that there are also other factors that drive how many hours you actually study. We could be interested to know whether drinking coffee makes any difference for example—and that irrespective of how often you go out per week. After a late night out, you might be more inclined to have coffee in the morning, so just measuring the coffee is not enough. We will have to control for your partyness.
Ideally our framework is capable of the following.
- Measure the strength of association between more than 3 variables in the sample, controlling for all factors.
- Measure the strength of association between more than 3 variables in the population, controlling for all factors.
- Measure the uncertainty we have about these association in the population.
7.1 Bivariate Regression
The framework for all that is called regression analysis. Let us build it up one step at a time.
What is regression analysis? In the literature you can find many descriptions.
- “Regression analysis involves making quantitative estimates of theoretical relationships between variables.”
- “A technique which involves fitting a line to a scatter of points.”
- “Regression represents a most typical association between two variables and can be considered analogous to the mean in univariate descriptive statistics.”
- “Regression tries to explain changes in one variable (dependent) as a function of changes in other variables (independent).”
- “Causality is implied.”
At the end of the day, what regression does is to fit a line that is closest to all observations. Which one of the three would you pick?
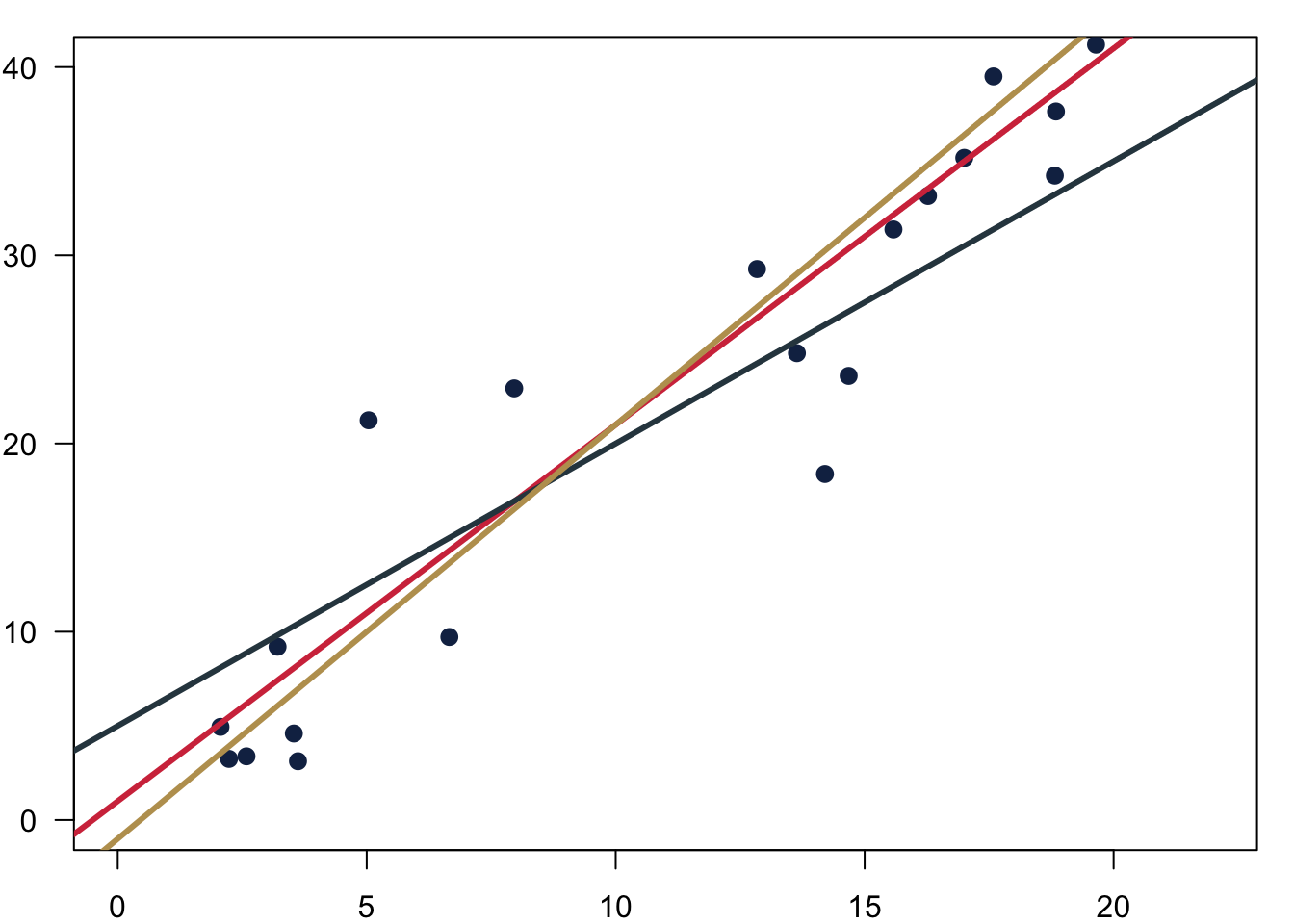
We want to chose the one that fits the data best so that we can express the relationship between the variables with a simple formula.
\[ Y = \alpha + \beta X \]
with
- Y the dependent variable
- X the explanatory variable
- \(\alpha\) the intercept
- \(\beta\) the slope
Fitting the line is easy with well behaved data. In the figure below you can see three different intercepts \(\alpha\) and we fit them to their respective data.
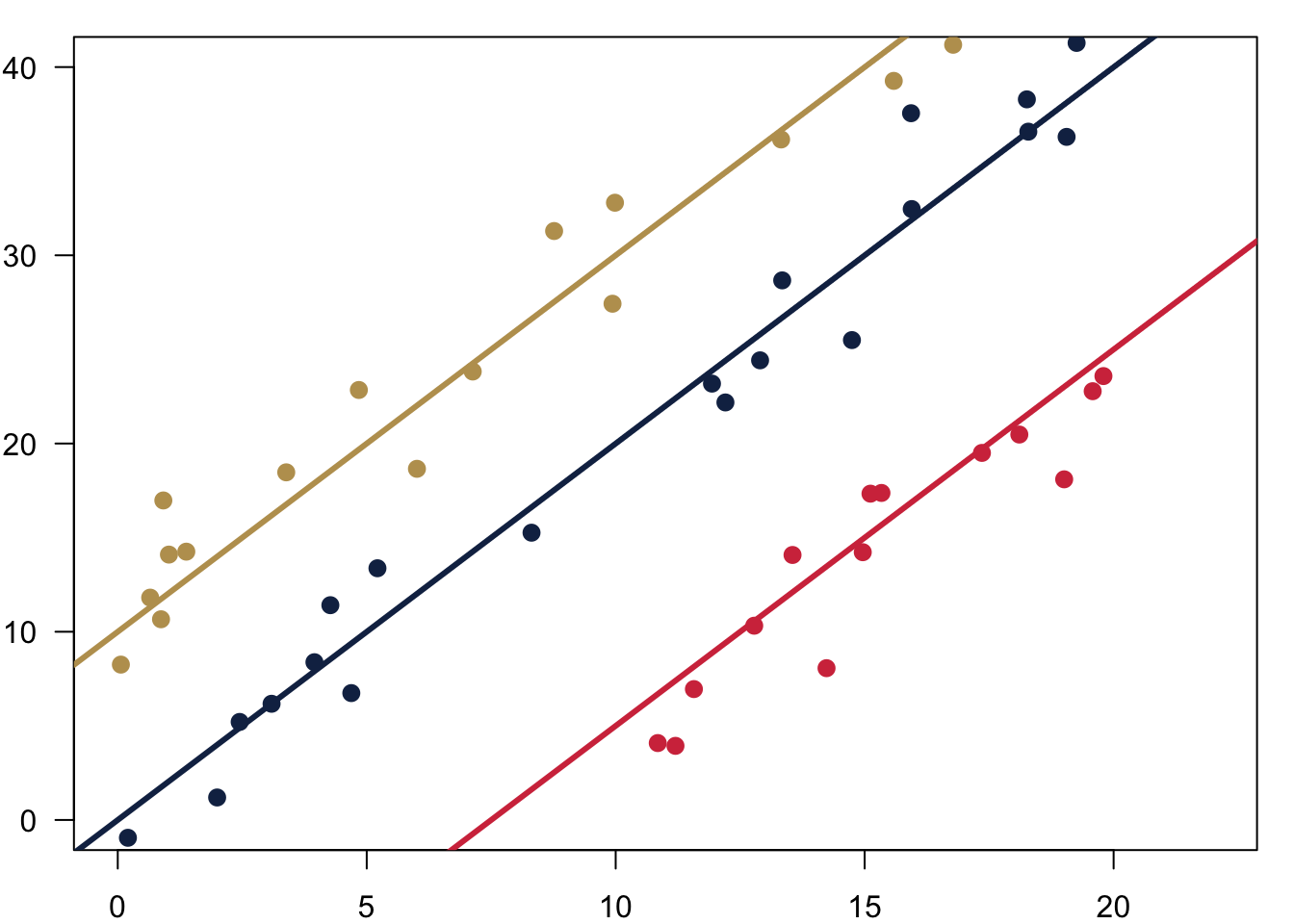
And here is how we could also fit different slopes \(\beta\) through the data.
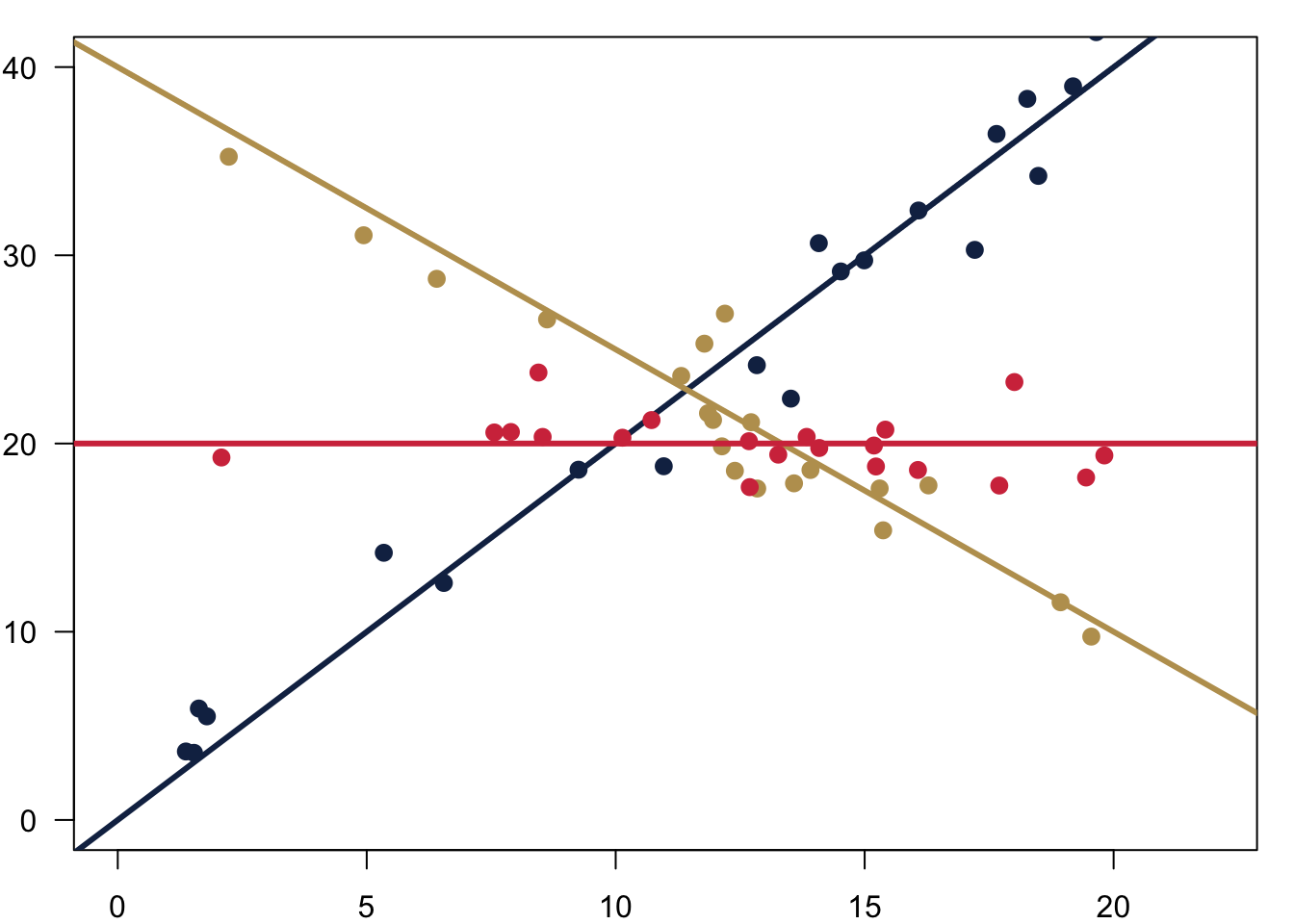
7.1.1 How Does It Work?
The big question of course is, how does this fitting work? The first thing we have to understand is that there will be an error to our estimation.
If an association between two variables were perfect, we would speak of a deterministic relationship. Take for example the conversion of temperature. If we want to calculate the temperature in Fahrenheit from Celsius, we can follow the easy formula
\[ \text{Fahrenheit} = 32 + (9/5 ∗ \text{Celsius})\].
Here, \(Y\) can be perfectly predicted from \(X\) using an \(\alpha = 32\) and a \(\beta = 9/5\).
In practice things often follow probabilistic relations which are inexact, so we need to account for this mistake with an error and add \(e\) to the formula.
\[ Y_i = a+ b X_i + e \]
If we fit such a line, we can calculate residuals. They are the difference between the actual value of \(y_i\) and the predicted value \(\hat y_i\) from the regression model. In the figure, you can see the residuals as red lines.
\[y_i − \hat y = e_i\]
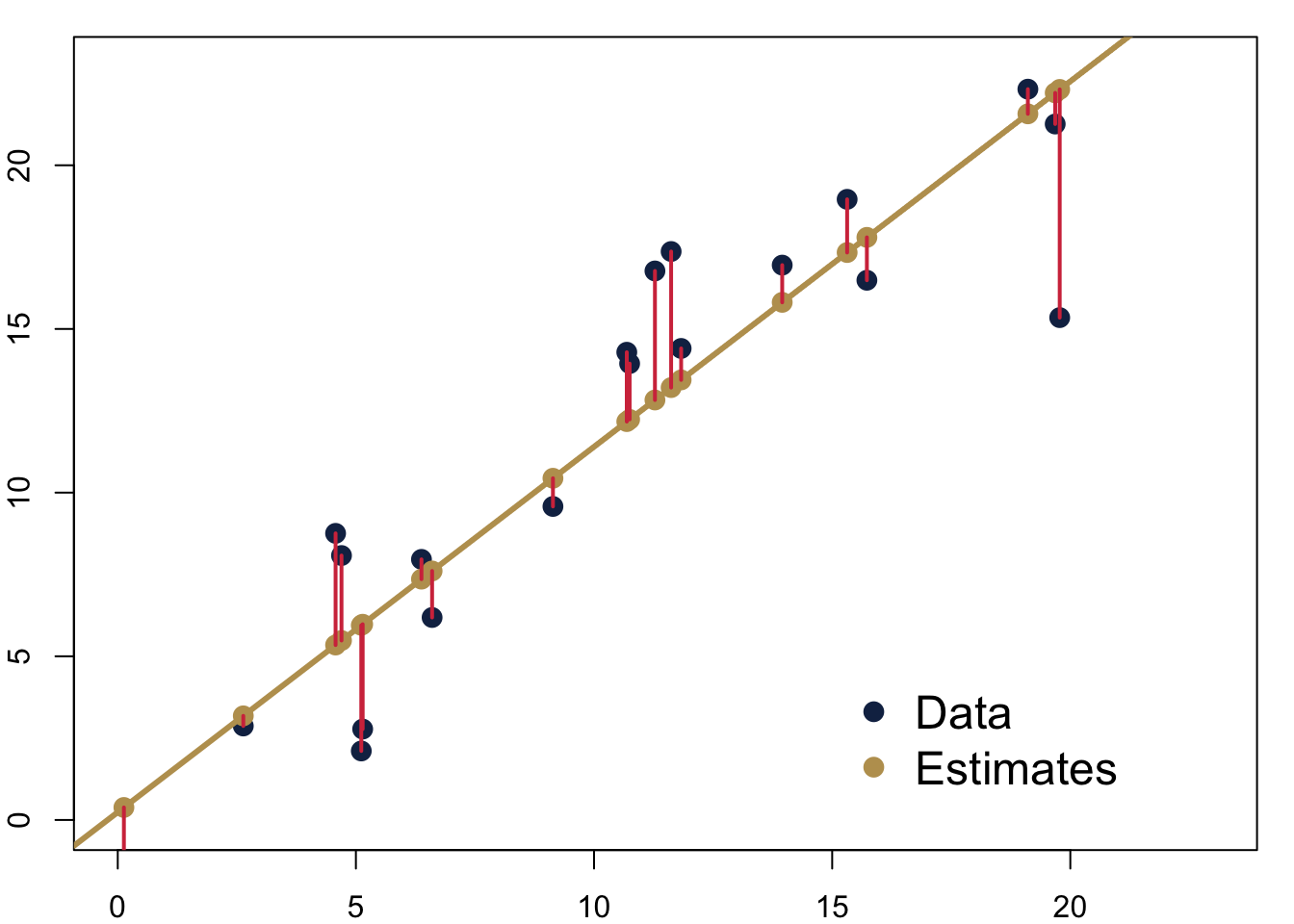
7.1.1.1 Fitting the Line
We can find the perfect line by fitting the line with a technique called Ordinary Least Squares (OLS). We choose the line that minimises the sum of the squares of the distances between each observation and the regression line.
\[ \sum (y_i-\hat{y_i})^2 = \sum {e_i}^2 \]
\(\sum {e_i}^2\) is also called the Residual Sum of Squares (RSS). To fit the regression line, we minimise the RSS. This is it.
Implementing this routine means we minimise the distance between our observation and the predictions on the line. In the figure above, we would minimise the (squared) length of the red lines connecting the predictions in yellow and the real data in blue.
Using this OLS estimator, we can calculate the slope \(b\).
\[ b = \frac{\text{covariation}}{\text{variance}} = \frac{\sum (x_i-\bar{x})\sum (y_i-\bar{y})}{\sum (x_i-\bar{x})^2} \]
Given we now know the slope \(b\) the intercept \(a\) is then really straightforward and
\[ a = \bar{y} - b\bar{x} \]
Let us calculate the parameters for a small data set with a regression by hand.
7.1.1.2 Inference
We fitted a line through our sample. We now know how to guess the best fitting line through our data. What can we say about the population that is behind our sample?
We will proceed in a similar way as we did when we were estimating the mean for a population last week. Of course, we do not know the population parameter for the intercept \(\alpha\) and the slope \(\beta\) and we actually will never be able to know it unless we were to ask every single individual in the population. But given that we have a random sample, we already have a good guess. The most likely values \(\hat \alpha\) and \(\hat \beta\) are the ones that we can calculate using our sample, so \[ \hat \alpha = a \] and \[ \hat \beta = b \].
7.1.1.3 Uncertainty
We also want to be realistic about the uncertainty of our estimate. Remember that we were calculating a standard error for a sample mean? And that we used it to then calculate the confidence interval around our sample mean? Back then, we used the standard deviation from our sample as the best guess. We will do the same for the two parameters \(\hat \alpha\) and \(\hat \beta\) here.
Let us begin with the standard error for our estimated slope \(\beta\). \[ Var(\beta_1) = \frac{\sigma^2_\epsilon }{\sum{(x_i-\bar x)^2}} \] \[ se(\beta_1) = \frac{\sigma_\epsilon}{\sqrt{\sum{(x_i-\bar x)}^2}} \]
This is how to calculate the uncertainty for the intercept \(\alpha\).
\[ Var(\beta_0) = \frac{\sigma^2_\epsilon \sum{x_i^2}}{n \sum{(x_i-\bar x)^2}} \] \[ se(\beta_0) = \sqrt{\frac{\sum{x_i^2}}{n \sum{(x_i-\bar x)^2}}} \sigma_\epsilon \]
Of course, we do not know \(\sigma^2_\epsilon\). But we will use the same trick like before and take the variance of the regression residuals.
\[ \hat\sigma^2_\epsilon = \frac{\sum \epsilon_i^2}{n-p} \]
Therefore,
\[ \hat\sigma_\epsilon = \sqrt{\frac{\sum \epsilon_i^2}{n-p}} \]
This yields the estimated standard error of the estimate—here \(\hat\beta_1\).
\[ \hat{se}(\hat\beta_1) = \frac{\hat\sigma_\epsilon}{\sqrt{\sum{(x_i-\bar x)}^2}} \]
With this estimated standard error, we can now calculate a t-score.
\[ t = \frac{\hat \beta}{se(\hat \beta)} \]
This t-score is conceptually quite similar to the z-scores we already know. It expresses a parameter that is standardised using its standard error. The beauty is that we know from statistical theory how it is distributed: It follows a t-distribution. This distribution is quite similar to the normal distribution, it is also bell shaped and symmetric.
Given that we know its distribution, we can again calculate p-values. We interpret them in just the same way as we were interpreting them for the means in a sample—this time however with regards to the regression parameters. Assuming that the true, unknown population parameter \(\beta\) is actually 0, how likely is it that we observe the estimated parameter \(\hat \beta\) that we do?
7.1.1.4 Assumptions
Just to mention, since we will not go into details here: We can unrol all this framework because we are making a number of assumptions about the data.
- The relationship between the dependent variable and the explanatory variables needs to be linear.
- The variance of the residual error must be constant
- The residual error must be normally distributed with a mean of 0.
- The expected value of the residual error must not depend on the data.
7.1.2 How Do We Interpret Results?
That was quite a bit. Let us take a look at some data to learn how to interpret results.
##
## Call:
## lm(formula = dat21$studyperweek ~ dat21$studyideal)
##
## Residuals:
## Min 1Q Median 3Q Max
## -7.842 -2.950 1.101 2.910 4.884
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.5548 3.0245 0.183 0.857082
## dat21$studyideal 0.6115 0.1410 4.338 0.000682 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.999 on 14 degrees of freedom
## Multiple R-squared: 0.5734, Adjusted R-squared: 0.5429
## F-statistic: 18.82 on 1 and 14 DF, p-value: 0.0006815The core idea of interpreting these results is that we can take a look at two things.
- What is the substantive effect? Remember that we have parameter estimates for our equation \(Y = \alpha + \beta X\).
- In addition, there is also the uncertainty around the parameter estimates that we will have to account for.
I am walking you through the interpretation via a video here.
7.2 Beyond Bivariate Regression
But the real reason we are here is to go beyond bivariate regressions.
7.2.1 Bivariate Regression Plus a Dummy
What is a dummy variable? Qualitative information often come in the form of binary information (zero-one variable). We call these kind of variables a dummy variable. The benefit of capturing qualitative information using zero-one variables is that it leads to regression models with easy interpretations.
Good coding practice: name your variable after the ‘1’ category; e.g. Female if the variable is coded 1 for female and 0 for male. Gender would be a confusing variable name.
7.2.1.1 How Does It Work?
Let us assume we examine the relationship between education and income among women and men and collect the following data.
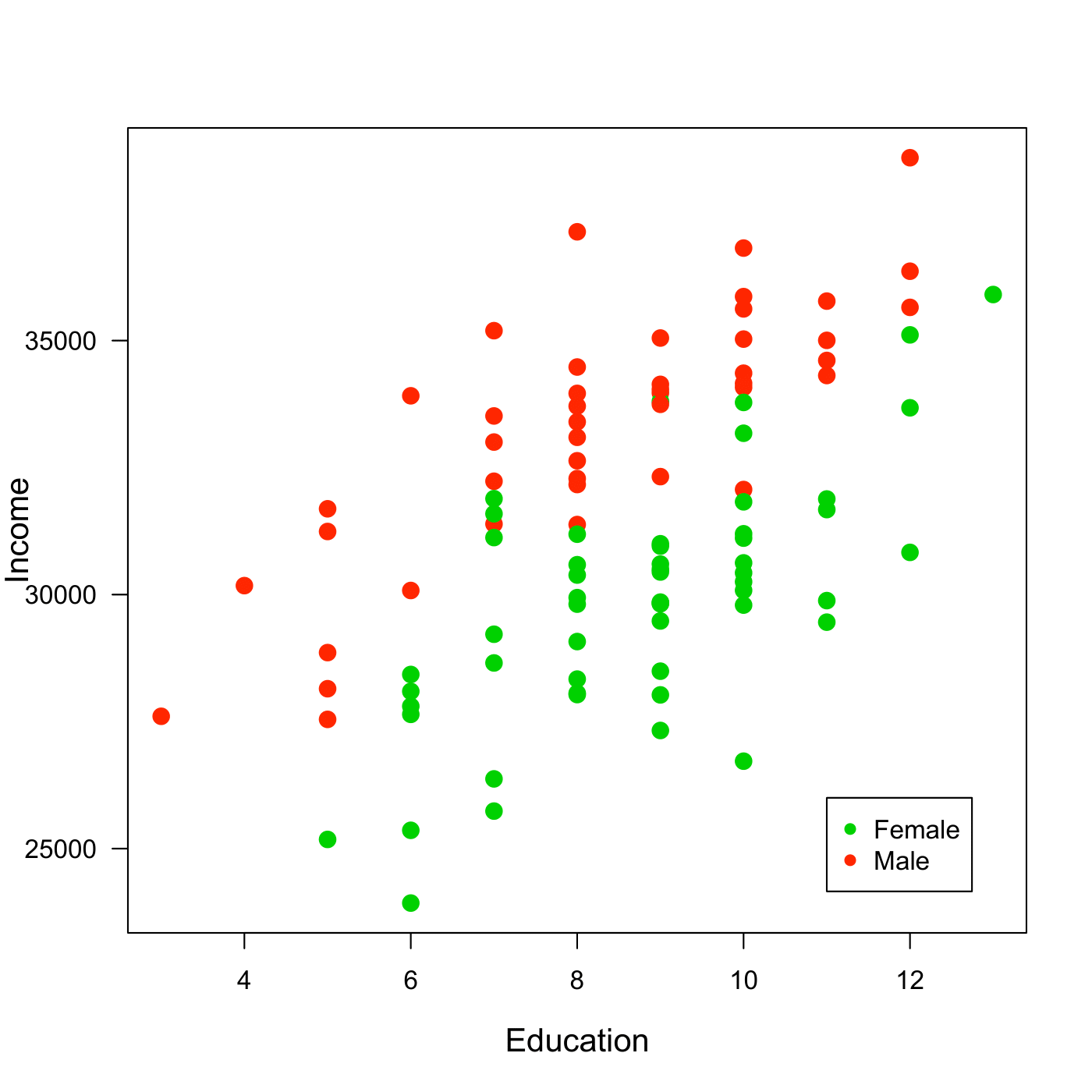
Figure 7.1: Data for Income, Education and Gender. Note: Artifical Data.
We want to examine the relationship between education and income among women and men. Our model will be as follows
\[Income = \beta_{0}+\beta_{1}*Education+\beta_{2}*Female \]
7.2.1.2 How Do We Interpret Results?
We can interpret \(beta_0\) and \(beta_1\) as before. But now there is also \(beta_2\). Its interpretation is fairly straightforward: it is nothing different than an intercept shift.
Suppose we fit the following regression model to our data:
\[ Income = 25934 + 894*Education - 3876*Female \]
We can see two regression lines, one for males and one for females. For the women we calculate \[ Income = 25934 + 894*Education - 3876*1= 22058+894*Education \]
And for the men the equation looks like follows.
\[ Income = 25934 + 894*Education - 3876*0 = 25934 +894*Education \]
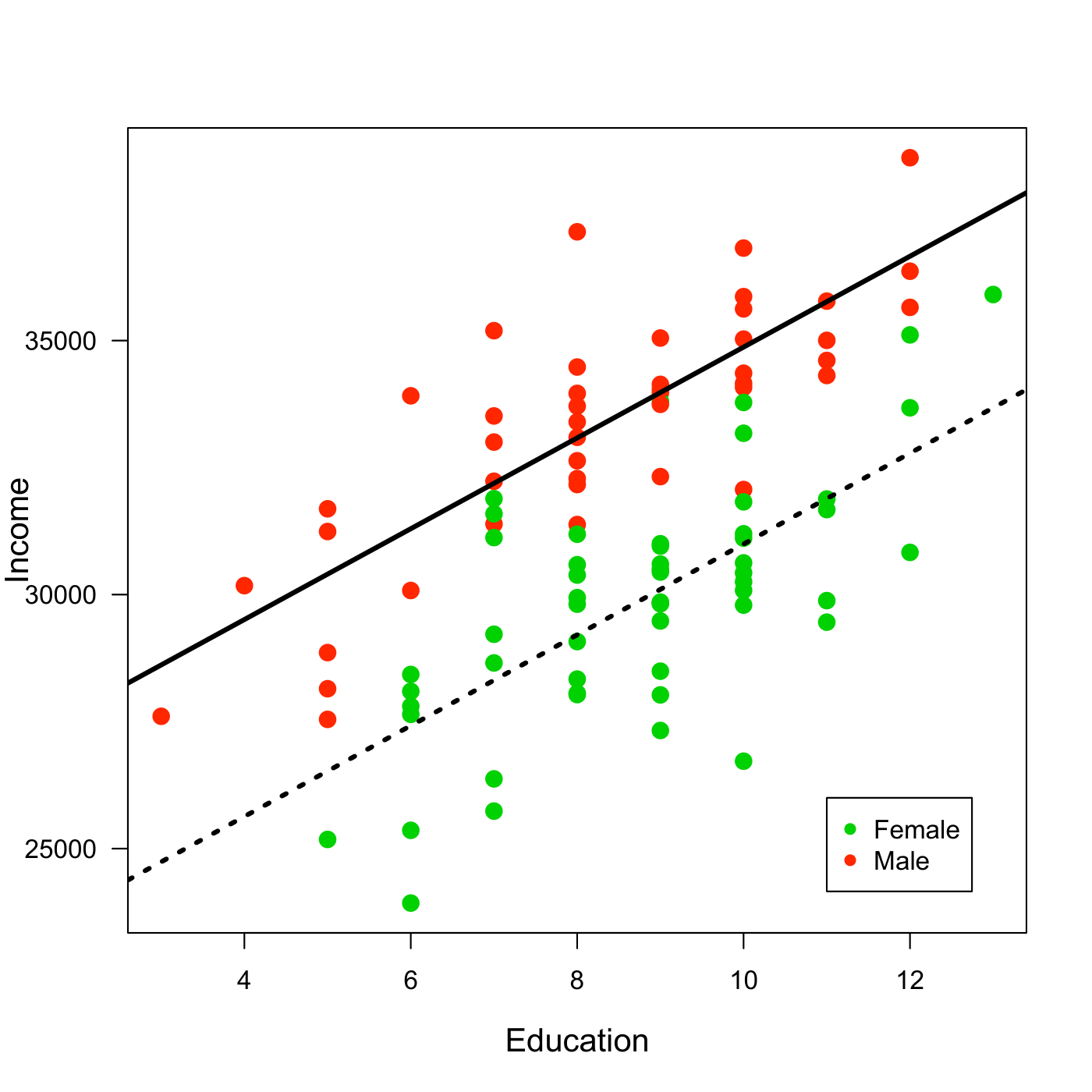
Figure 7.2: Regression through the data for Income, Education and Gender. Note: Artifical Data.
For example, we expect that a woman with 15 years of education earns earns on average.
\[ Income = 25934 + 894*15 - 3876*1 = 35468 \]
7.2.2 Multivariate Regression
We can of course go beyond just adding one dummy variable and one continuous variable to the regression equation—in fact you can add more than one from any variable to the regression equation. In the following example we will take a look at how that could look like.
7.2.2.1 How Does It Work?
Let us examine the relationship between economic growth prior to an election, the approval for the president and the vote share received by the incumbent presidential party in the US. This is how the data looks like.
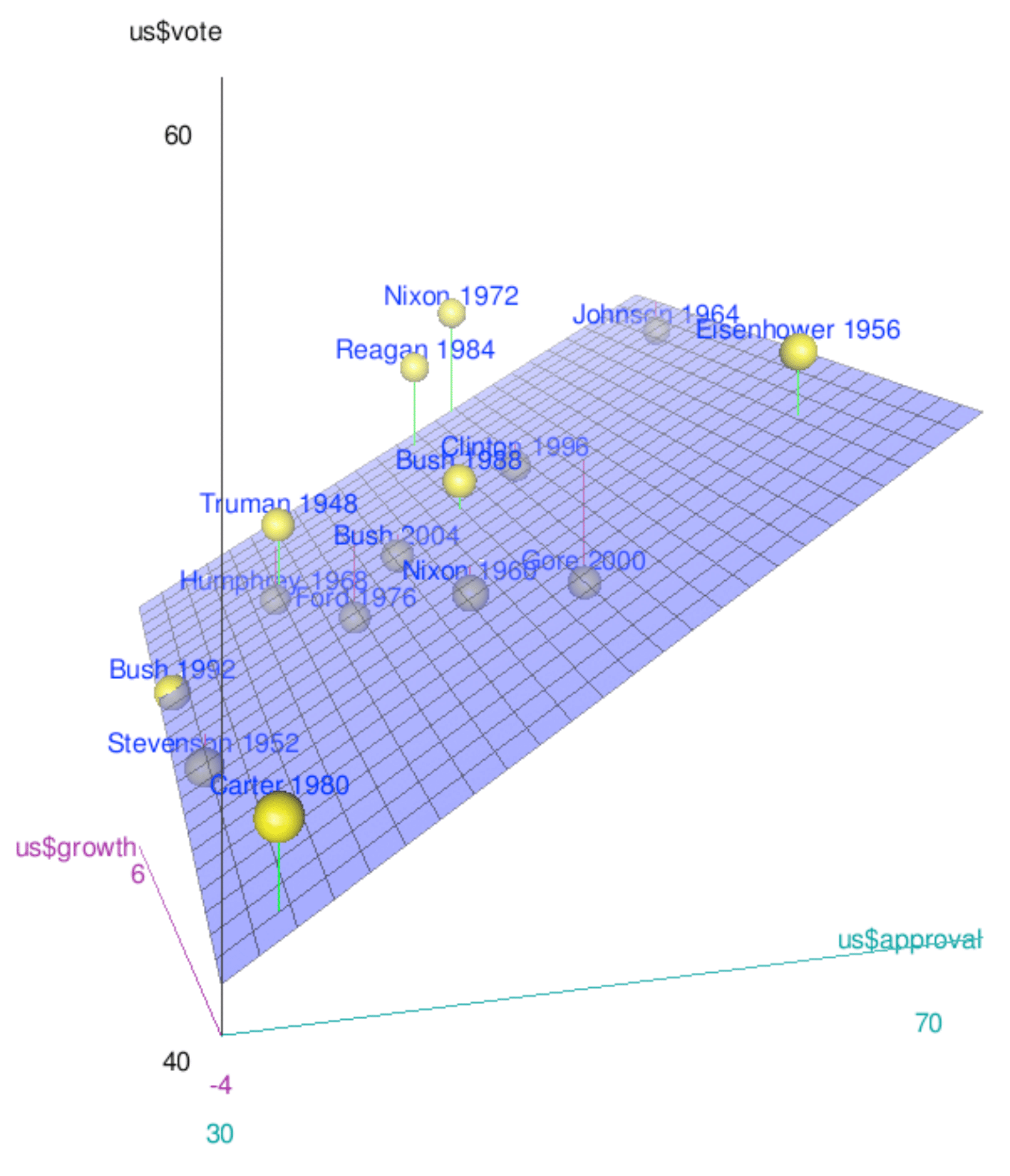
Figure 7.3: Data on Presidential Elections in the US.
The vote share is on the vertical axis. We also have data for approval rating and for economic growth on the other two axes. Our model then becomes:
\[ \text{vote} = \beta_{0} + \beta_{1} \text{growth} + \beta_{2} \text{approval} + e \]
When we estimate regression model with two explanatory variables, we are effectively estimating the best fitting plane through the three dimensional data cloud. This works just as before: we will use the OLS estimator.
7.2.2.2 How Do We Interpret Results?
These are the results of our regression equation.
##
## Call:
## lm(formula = us$vote ~ us$growth + us$approval)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.4076 -1.1555 -0.8039 2.1181 4.2504
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 34.82929 2.77295 12.560 2.90e-08 ***
## us$growth 0.81459 0.27126 3.003 0.011 *
## us$approval 0.31950 0.05603 5.702 9.88e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.644 on 12 degrees of freedom
## Multiple R-squared: 0.808, Adjusted R-squared: 0.776
## F-statistic: 25.25 on 2 and 12 DF, p-value: 5.01e-05For the interpretation, let us visit a quick video again.
If you want to download the data to play around with it yourself, you can find it on Learning Central.
7.3 The Relevance of Statistical Control
When we plot data, we usually do this in two dimensions. Any relationship between those two variables is then easy to observe. However, if more dimensions belong to the data set, things might be a bit more tricky.
When we analyse data, each variable that we have in our spreadsheet adds another dimension to the data overall. We already saw how this can look like in the example with the presidential elections. For the data analyst, this means that the true relationships might hide themselves in the multiple dimensions.
To illustrate that, here is some artificial data that I made up for you. You can see relationship between education in years and income per year.
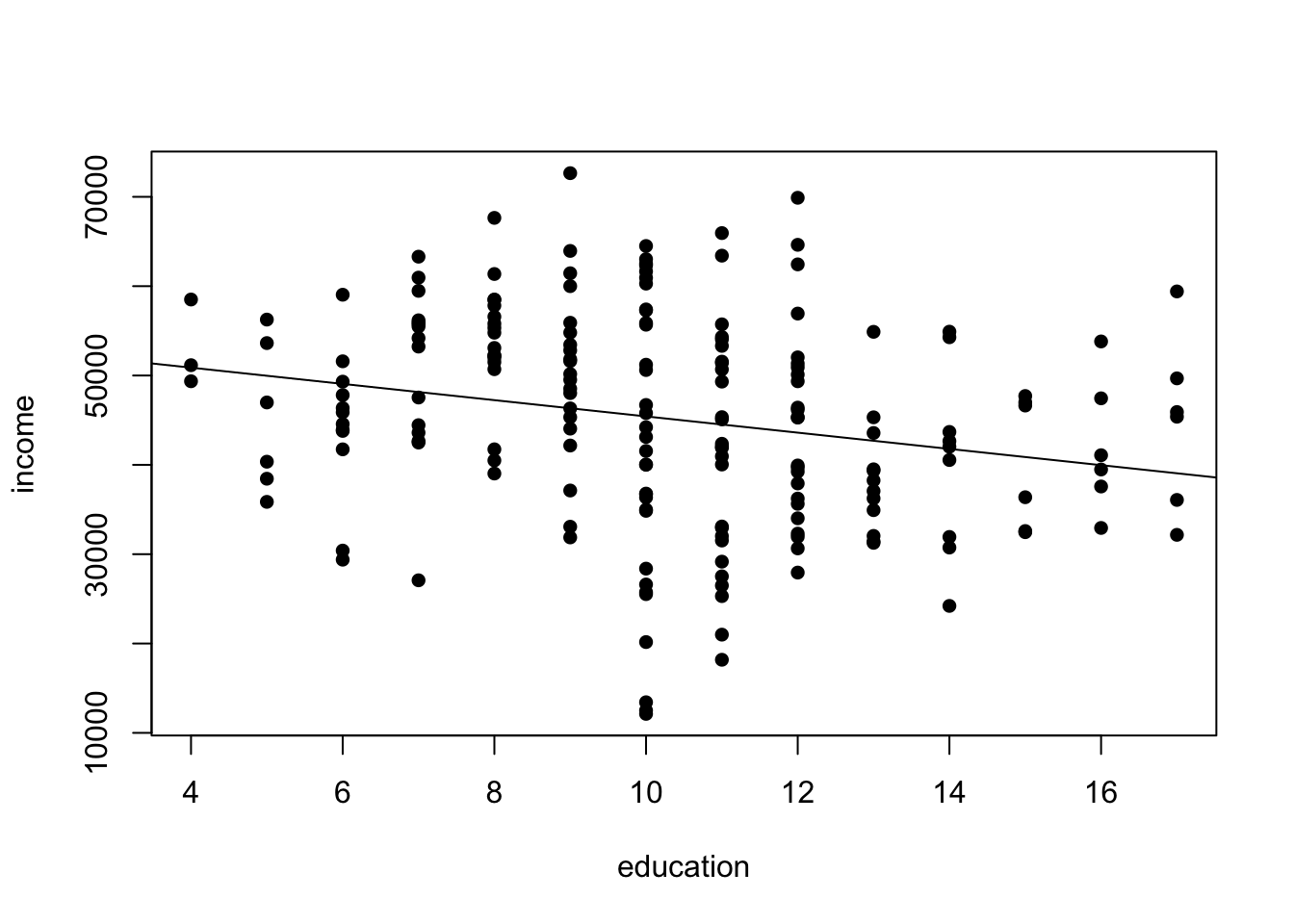
The relationship seems to be fairly clear: there is a negative relationship in the data. The more you are educated, the less you earn. Substantively, this looks a bit odd, right? But if you were a naive data analyst, you might still take the data for granted. You could even run a regression on that and get a clear result.
##
## Call:
## lm(formula = income ~ education)
##
## Residuals:
## Min 1Q Median 3Q Max
## -33304 -7259 465 7609 26309
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 54534.1 2947.3 18.503 < 2e-16 ***
## education -910.5 275.5 -3.304 0.00113 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 11350 on 196 degrees of freedom
## Multiple R-squared: 0.05276, Adjusted R-squared: 0.04793
## F-statistic: 10.92 on 1 and 196 DF, p-value: 0.001133Data cannot lie, right? So this the higher the education, the less you earn. This is what you would believe?
Let us dig a bit deeper. In our data, we also have a variable that stores the information about the gender of the individuals. Let us add this information with some colour to our data.
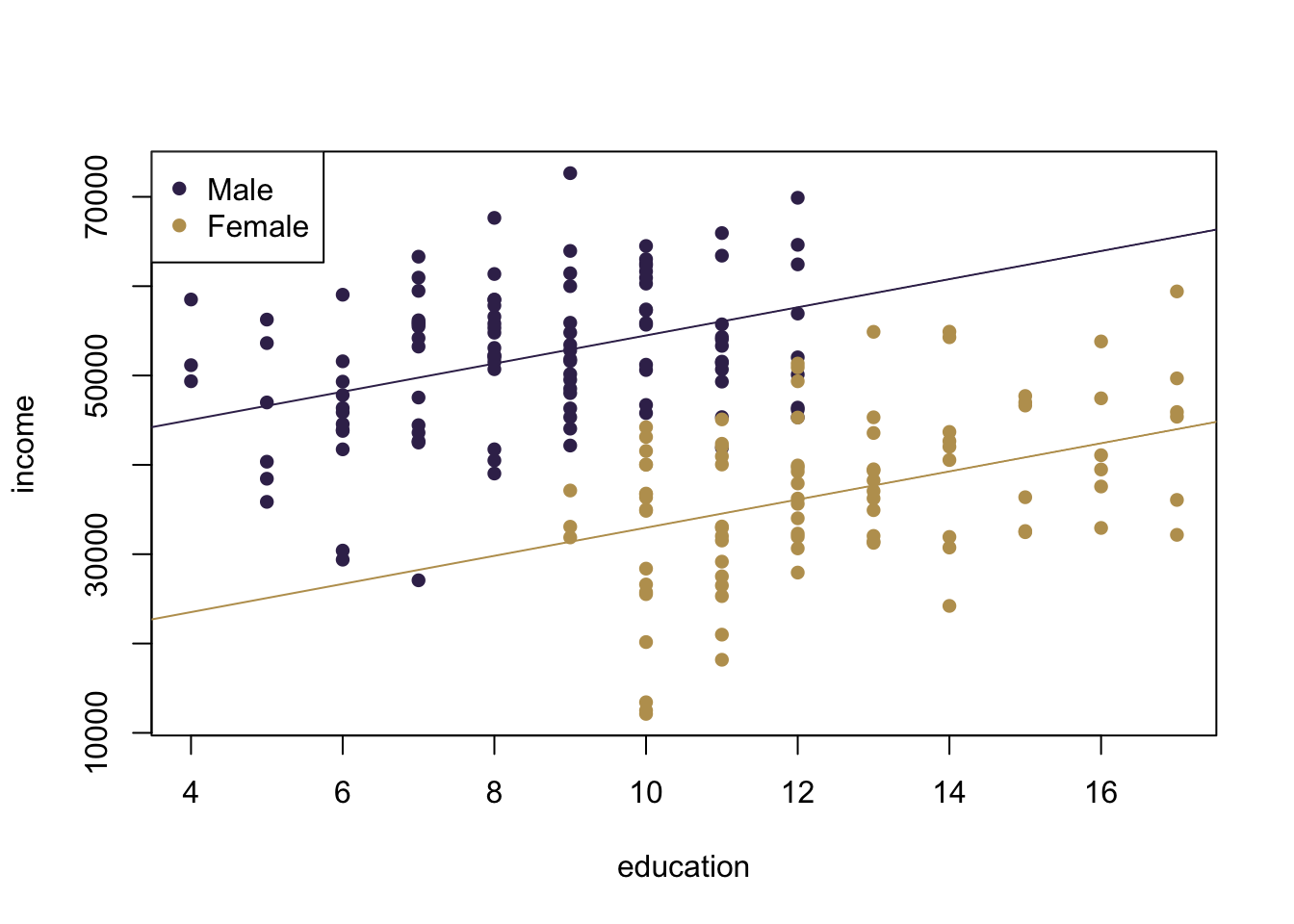
Now, the picture looks quite different. There is a clear pattern going on. First, men seem to be earning much more. In addition, there is also something standing out clearly in the data: men have less education. The multivariate regression tells us the same story.
##
## Call:
## lm(formula = income ~ education + male)
##
## Residuals:
## Min 1Q Median 3Q Max
## -22687.6 -5649.2 499.5 6086.9 19731.0
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 17211.1 3478.0 4.949 1.61e-06 ***
## education 1576.6 270.3 5.833 2.24e-08 ***
## male 21517.8 1589.0 13.541 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 8169 on 195 degrees of freedom
## Multiple R-squared: 0.5118, Adjusted R-squared: 0.5068
## F-statistic: 102.2 on 2 and 195 DF, p-value: < 2.2e-16Men earn on average 21517.79 more than women—controlling for any influence from education. And for each year in education, you earn 1576.56 more—and here we take the gender of the individual into consideration.
Statistical control allows us to make these statements about the relationships of variables. But we not only restrict ourselves to two variables, we can account for the influence of every other variable that we have in the equation, too.
7.4 R Code
The R code we are learning is really simple this week. Remember, R is built for statistics, so estimating a regression is as simple as follows.
# Load the data
load('../other_files/preparing_data/data/uspresnew.Rdata')
# estimate a model
model1 <- lm(us$vote ~ us$growth + us$approval)
# Get the results from the regression
summary(model1)##
## Call:
## lm(formula = us$vote ~ us$growth + us$approval)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.4076 -1.1555 -0.8039 2.1181 4.2504
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 34.82929 2.77295 12.560 2.90e-08 ***
## us$growth 0.81459 0.27126 3.003 0.011 *
## us$approval 0.31950 0.05603 5.702 9.88e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.644 on 12 degrees of freedom
## Multiple R-squared: 0.808, Adjusted R-squared: 0.776
## F-statistic: 25.25 on 2 and 12 DF, p-value: 5.01e-05If you save the model summary, you can easily extract some results for later use. For example, you could use the parameters to plot a regression line through your data—here for the bivariate case.
model2 <- lm(us$vote ~ us$approval)
summary.model2 <- summary(model2)
a <- summary.model2$coefficients[1]
b <- summary.model2$coefficients[2]
plot(us$approval, us$vote, pch = 16, xlab = 'Approval',
ylab = 'Vote Share', las = 1)
abline(a=a, b=b, col = cardiffred)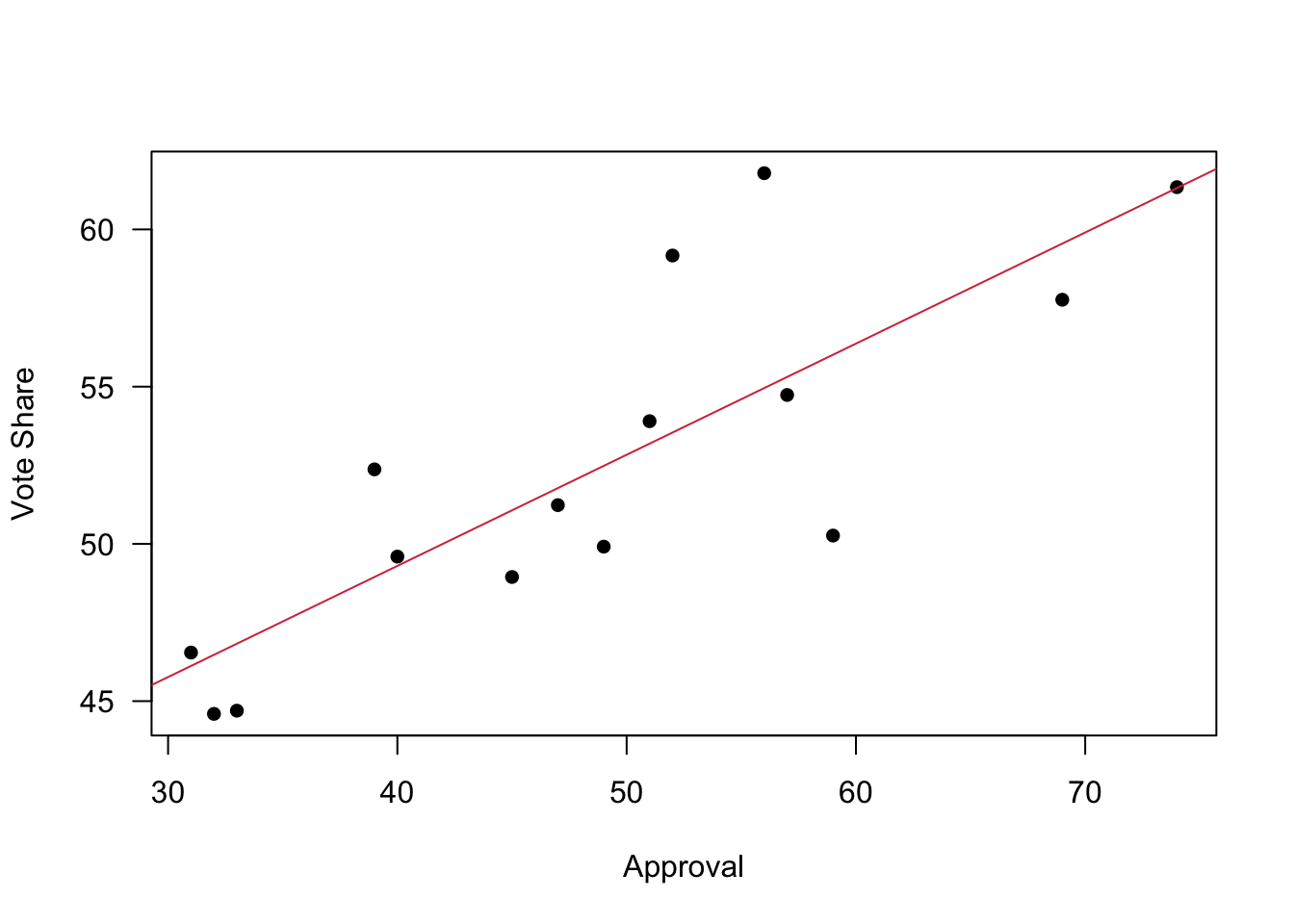
7.5 Reading for This Week
This week, please take a look at chapter 11 in Fogarty (2019).